Scientific Benchmarking Datasets¶
Datasets: Types and cross-references¶
OpenEBench data types are defined in the data model, within the ‘Dataset’ schema. These types correspond to the different types of datasets that are used during the lifecycle of a benchmarking event. There are 7 types of datasets defined in the data model:
Public Reference data sets. They are a widespread, publicly available and well characterized data set which can be used by developers and/or interested users to gather performance data of their systems in a controlled set-up. Scientific communities tend to make available Public Reference data to facilitate the engagement of participants within the challenges at hand. These data sets could comprise data from previous benchmarking editions but it is highly dependent on the community and the scientific problem at hand.
Input data sets. Represent the data sets to be processed as input by participants in the benchmarking activities. Those data sets can be publicly available for download at specific repositories e.g. UniProtKB specific reference proteome sets for the Quest for Orthologs participants; and/or can be submitted automatically by benchmarking platform e.g. CAMEO, to participants web-servers. Input data sets should follow at least the same data formats as the Public Reference data sets, and should provide enough metadata describing the data sets to facilitate reproducibility, data provenance and, potentially, the evolution of participants across different benchmarking challenges editions with different input data sets of varying degrees of complexity.
Participant data sets. These data sets represent the data e.g. predictions, produced by participants given a specific Input data set associated to specific benchmarking activities. Depending on the level of automation, participant data sets can be submitted manually e.g. uploaded to a server, and/or automatically e.g. response via APIs implemented in systems like BeCalm. Unless previously agreed, participant data sets are often kept private to participants and/or communities. It would be recommendable that participant data sets which are part of scientific benchmarking publications should be made available for reproducibility purposes, data reuse in downstream analysis and/or further meta-analysis.
Metrics Reference data sets. These data sets contain data used to evaluate the benchmarking process, i.e. the “true” responses to the challenges. These data sets are often kept private by benchmarking events organizers while a challenge is active. This standard practice prevents participants from adjusting their systems to have the best performance for very specific data sets, which is often referred to as overfitting. Overfitting may render systems useless and not-fit-to-purpose and, therefore, it is highly discouraged. Depending on the nature of the Metrics Reference data sets, those can be either “Gold data sets” or “Silver data sets”. It is not uncommon to have both types of data sets as part of a Benchmarking event. When available, Golden data is desirable because it represents the ultimate data that any system should aim to produce. For instance, in the case of Protein Structure Predictions the experimental data deposited in the Protein Data Bank (PDB) is considered to be the “Gold data” for the benchmarking activities carried out by communities such as CAMEO, CASP, and CAPRI. In the absence of a gold standard, benchmarking efforts have to resort to “Silver data”. For instance, synthetic and/or simulated datasets generated in silico following previous experiences or with data generated using unsupervised learning approaches, based on the consensus among different —i.e. algorithmically independent — methods. For the latter, naive methods e.g. Bayesian networks, can provide a baseline allowing assessors to measure relative performance between methods with, on average, moderate to good accuracy. Such consensus data is referred to as “Silver data”. However, data from silver standards should be used with caution as it needs to be revised regularly to adequately evaluate new developments in the field. Often Metrics Reference data sets become public e.g. Public Reference data sets, once a given challenge has concluded because of its intrinsic value to address valuable scientific challenges.
Assessment data sets. These data sets are produced after applying specific metrics e.g. True Positive Rate, to participants data sets while considering metrics reference data sets. Assessment data sets establish how close or far are participants from the expected results. Often preliminary assessment data sets tend to be private to each participant e.g. understanding the initial characteristics of the platforms and/or metrics reference data sets nature; while final assessment data sets tend to be shared among benchmarking participants before the challenge ends, and made public once the events end. Even when participant data sets are not available, assessment data sets can be very useful to measure the performance evolution of different systems versions for the same challenge and/or the complexity of different reference metrics data sets for the same system. Ideally, assessment data sets would allow to track the evolution of both reference metrics data sets and systems versions. However, it would be nearly impossible to deconvolute the impact of each variable into the final results.
Aggregation data sets. These data sets are considered metadata sets grouping either i) assessment data sets from different participants for the same reference metrics data set and applied metrics, ii) assessment data sets from the same participant but for different reference metrics data sets and/or applied metrics in the same benchmarking event, or iii) the grouping of the assessment data sets from the same participant and the same applied metrics across different benchmarking events. Aggregation data sets are the foundations of the community-led scientific benchmarking activities as they offer an unified framework to compare participants performance among themselves for a specific scientific challenge and/or the evolution of individual participants along time. Aggregation data sets allow data bundling and are the ones consumed by experts and non-experts for taking decisions on what systems to use for their own scientific problems. Aggregation data sets can be directly offered at OpenEBench using available views e.g. experts and non-experts data views; and/or using available APIs. Those data sets due to their own nature would be mostly public although they might remain private to scientific communities and/or benchmarking participants while challenges remain open.
All those types are used in the different steps of a benchmarking
experiment, so they can be interrelated (for data provenance) and
cross-referenced from the other concepts (e.g. MetricsEvent defines the
step from a participant dataset to an assessment dataset). The following
figure illustrates how the different dataset are connected through
TestActions.
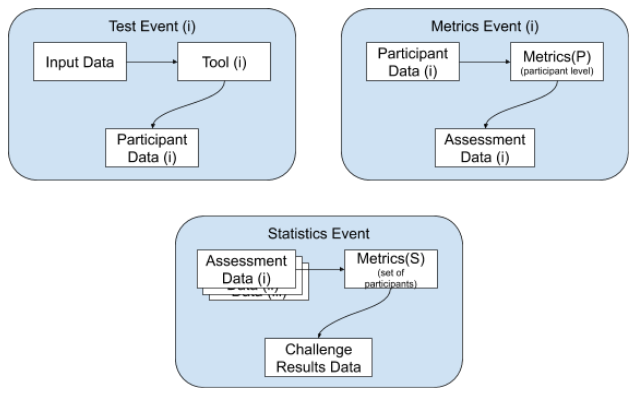
TestActions can have very different roles. The role is determined by the action type:
TestEvent defines the transition from an input dataset to a participant dataset. In the benchmarking cycle it corresponds to the process when the participant makes its predictions.
MetricsEvent defines the transition from a participant dataset to an assessment dataset. In the benchmarking cycle, it corresponds to the evaluation of the participant’s submission, that is, the computation of the metrics.
AggregationEvent defines the transition from one or more assessment dataset into a single aggregation dataset. In the benchmarking cycle, it corresponds to the consolidation of the benchmark, when - usually the community manager - brings together the results from all the participants and prepares them for visualization.
Datasets: Accessibility¶
Despite the nature of each data set, it is crucial that all data sets which are part of community-led scientific benchmarking efforts become public during their data life cycle. This effort will incentive open discussions and decisions within the community around which scientific challenges are relevant. Moreover, those efforts can be re-used by other communities and maximizing the data added value. Here, only assessment data sets can be published along with the assessment workflow, making sure that the original data cannot be reconstructed, e.g. for very small datasets. As a general rule, data should follow the FAIR data principles (Wilkinson et al. 2016), which states how to make data Findable, Accessible, Interoperable and Re-usable. This is part of a general movement in favor of implementing the principles around Open Science, Open Data and Open Source.
When defining reference data sets the data ownership is an important aspect. In order to avoid systems overfitting, communities might decide to conduct specific experiments to generate Input and/or Metrics Reference data sets, which are used for specific benchmarking events. In those circumstances and until data is publicly released e.g. via a scientific publication, data is private to the organizers and benchmarking participants should honor that. Thus, a legal mechanism to regulate data ownership and use is highly relevant. Specifically, participants should accept a legal binding agreement which prevents them to use accessed data for purposes different to participating in the benchmarking activities at hand. ~~CAMI (Critical Assessment of Metagenome Interpretation) already implements such policy to guarantee that participants honor such agreement. However, their system cannot change the status easily, given that there is a manual validation of scanned documents step before participants gain access to data.~~
Another important aspect for supporting benchmarking activities carried out for scientific communities is how data is accessed and shared through OpenEBench and associated APIs. As stated before, data should be made publicly through the data life cycle unless ethical and/or legal aspects prevent that. However, the system should be flexible enough to offer scientific community members, organizers and participants control over how data is accessed and distributed at any point in time. Thus, we propose four different data accessibility models in OpenEBench:
Private. This is the most restrictive accessibility model in OpenEBench. In this mode, only the data owner have access to this data as well as the data derived from it, e.g. Assessment data obtained when processing participants data. This accessibility model will facilitate participants to compare themselves with already existing data in a specific Benchmarking event, and might be useful at the initial stages of benchmarking challenges when it is needed to make sure that submitted data is behaving as expected.
Restricted. This accessibility model allows users to share data sets using URLs. This is a very convenient mechanism to foster collaborations among developers of distributed systems as well as to communicate results with restricted audiences e.g. among peers when a scientific manuscript is submitted.
Community based. This is the default accessibility model when a Benchmarking event is on-going. This model allows participants to share and/or compare their system performance, e.g. Assessment and/or Challenge data sets, on real time among community members. This will facilitate open and transparent discussions among community members and it can also facilitate the detection of potential flaws in the setting up of the ongoing event.
Public. This is the default accessibility model for already closed Benchmarking events. This visibility mode allows different stakeholders to have access to data e.g. Assessment and/or Aggregation data sets, and data transformations associated to them, for instance transitions between experts and non-experts views applying different classification algorithms. Making publicly available data is not constrained to finalized Benchmarking events because participants and/or events organizers can make data under their responsibility public. Importantly, once a data set is made public, it should be maintained as such to avoid potential confusion across stakeholders.
Independently of the visibility mode, data should follow the FAIR principles e.g. use of persistent and unique identifiers, because it should be possible to change the visibility mode among available ones e.g. private data could be made available to a whole community; restricted access data can be made publicly available, etc. Moreover, data should be interoperable at any time in and outside OpenEBench to facilitate their access, secondary analysis and/or further re-use by communities running scientific benchmarking activities. OpenEBench will work closely with the ELIXIR Data Platform to identify the most suitable long-term data repositories for data generated at the platform.