Scientific Benchmarking Data Model¶
In an effort to standardize the benchmarking process per se, we have developed a refined data-model to reflect the process itself and allow scientists to refer to a particular step and/or data set in a defined way.
OpenEBench Benchmarking Data Model defines the structure of a whole benchmarking process that takes place in the platform. It uses JSON Schemas, based on JSON Schema Draft 04 standard, to validate the objects that are used in the different communities benchmarking services.
Those objects structured to model the elements that come into play in a benchmarking service; and they also have properties/keys that are used to set the values for a particular community and results, or to connect objects between each other.
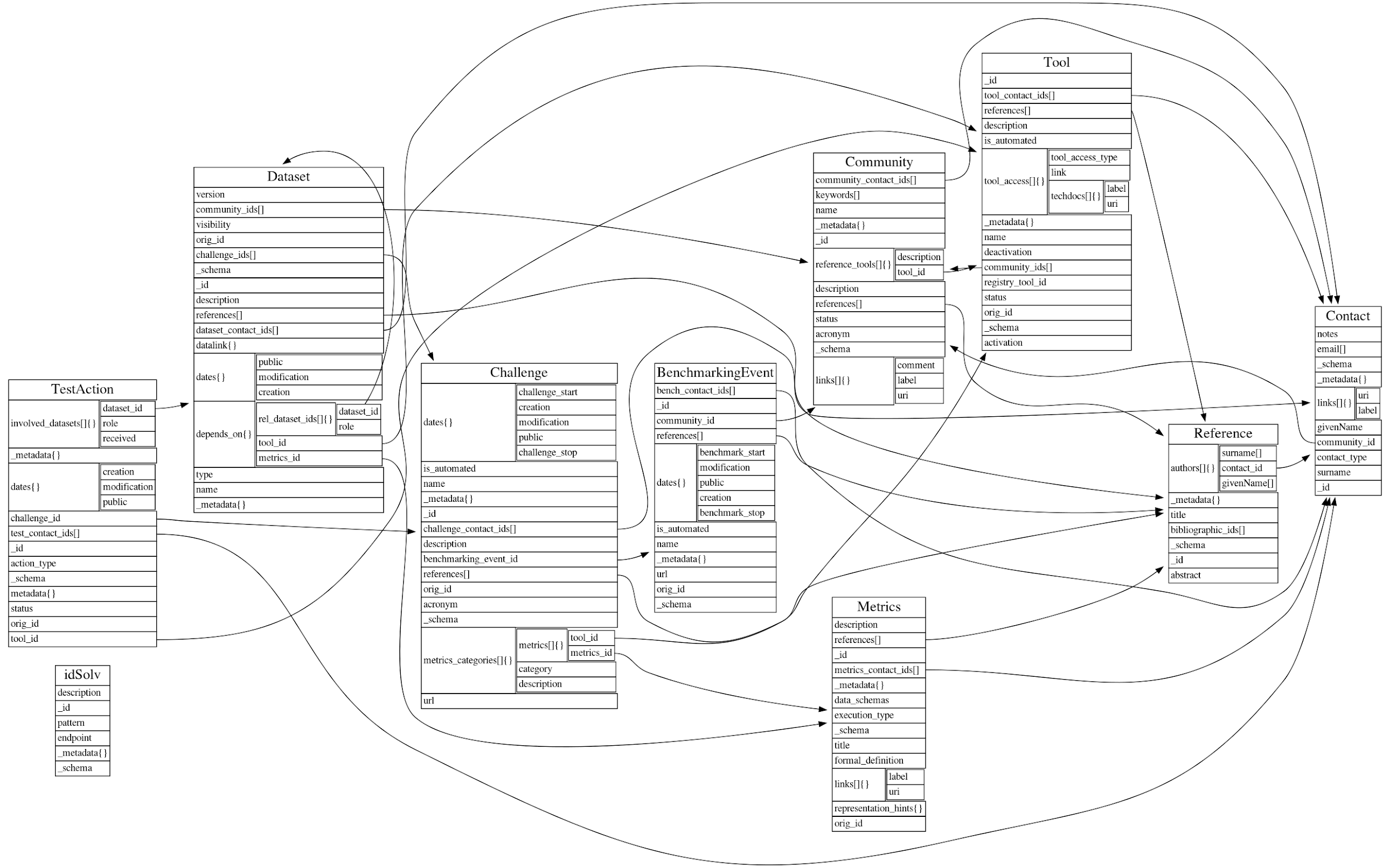
The schemas that are currently considered in the model (version 1.0) can be found in our data model’s repository. Here is a short description about each of them:
Community: The description of a benchmarking community, like CASP, CAFA, Quest for Orthologs, etc…
Contact: A reference contact of a community, tool, metrics or any other object.
Reference: A bibliographic reference, used to document a community, a contact, a tool, a dataset, a benchmarking event or metrics.
Tool: Software which can be used in the lifecycle of one or more benchmarking communities. Can be a participant in a particular benchmarking challenge, or software used to perform the benchmark itself.
Metrics: Defined metrics which can be computed from a dataset. Could be, for instance, the numerical values indicating some tools performance.
Dataset: Any one of the datasets involved in the benchmarking events lifecycle. So, they can be interrelated (for data provenance) and cross-referenced from the other concepts. There are 7 types of datasets defined in the model, which correspond to the specific data used in the different steps of a benchmarking event (e.g. metrics_reference, participant…) They are further explained in the data types section.
BenchmarkingEvent: A benchmarking event is defined as a set of challenges coordinated by a community, either attended or unattended.
Challenge: A challenge is the evaluation strategy defined by the community. It can be defined by a set of one or more metrics, reference datasets and test actions, related to the participants involved in the challenge.
TestAction: The involvement of a tool in a challenge, taking as input the datasets defined for the challenge, and generating the result datasets in the format agreed by the community. The generated datasets are later related to metrics datasets, which are the metrics agreed by the community for the challenge, used later to assess the quality of the result.
idSolv: This side concept is used to model CURIE’s which are not yet registered in identifiers.org.
Sample JSON files can be validated against these schemas using scripts located in extended JSON Schema validators repository or the online tool JSON Schema Validator.
Find more about the benchmarking data model in our Github repository (https://github.com/inab/benchmarking-data-model).